

Vanilla RAG? Cute. These days, if you ain't on knowledge graphs, you are missing out. But blink and they too will become tragically outdated.
Trying to learn about knowledge graphs in the context of retrieval-augmented generation (RAG) — or, frankly, anything else in the AI domain — can be an overwhelming experience. Alas, even if you grab the latest hottest research paper and throw it at your data, there is no guarantee you'll observe practically useful LLM outputs [1] [2]. A more reasonable approach is to build a custom solution, starting with fundamentals.
Luckily fundamentals don't change very much from paper to paper, and most of them have roots that are decades old. Let's review them to understand the place of knowledge graphs in the AI ecosystem, when to use them, and learn about the tradeoffs.
We'll start with the baseline.
What's a RAG
A retrieval-augmented generation (RAG) system is one in which you inject additional contextual information into the prompt and then ask the LLM to generate an answer taking that information into account [3] [4].
Consider the common scenario where this contextual information comes in a large collection of textual pieces. How many — and which ones — should you include in the LLM prompt? At the onset of e/acc, many believed the best strategy was "as many as possible." However, even as context windows grow, the effective attention span of LLMs remains limited [5], [6], as does their capacity for complex reasoning [7]. Today, the consensus is that you'll get better results by using a retrieval mechanism that includes only essential pieces of context for the task at hand. This maximizes the signal-to-noise ratio in your final LLM prompt, enabling the model to reason better.
Using vectors
One such mechanism involves cutting the blob of text into smaller chunks of text, and then taking only the chunks that are most "similar" to the text query.
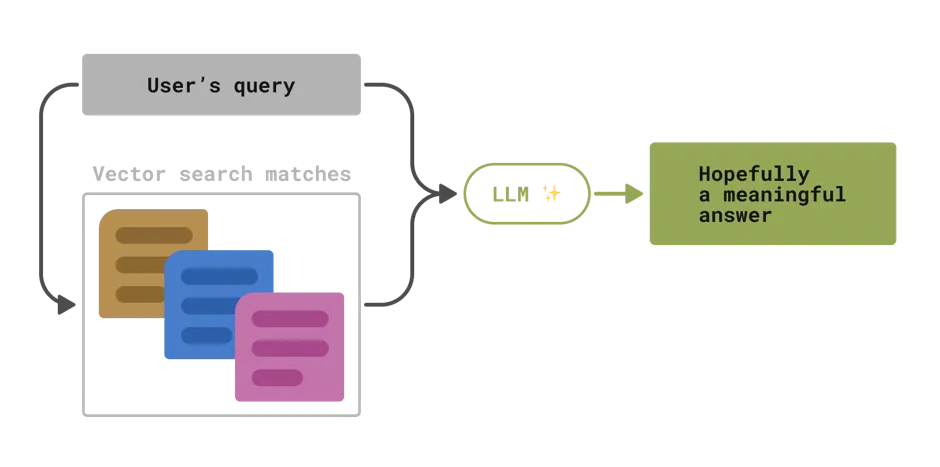
The traditional approach to this is to use full-text search (FTS). With the advent of transformer models there is a now a new way: vector search. It is done by translating all text (words) to a vector space (numbers) using a neural network, and calculating a mathematical distance between resulting vectors as a measure of similarity.
Both FTS and vector search allow you to store your text data in a database and query it based on content alone, with no assumptions about the internal structure or the domain of the data. A neural network, without additional guidance, does not care if your text is about feeding cats or selling cars. This lack of structure offers wonderful flexibility but is quite hard to fine-tune for your specific use case.
Using data structures
Another approach is to extract information from your blob of text into some kind of data structure. You can then design an algorithm to find relevant data, which can be much more efficient, predictable, and controllable than naive vector similarity search.
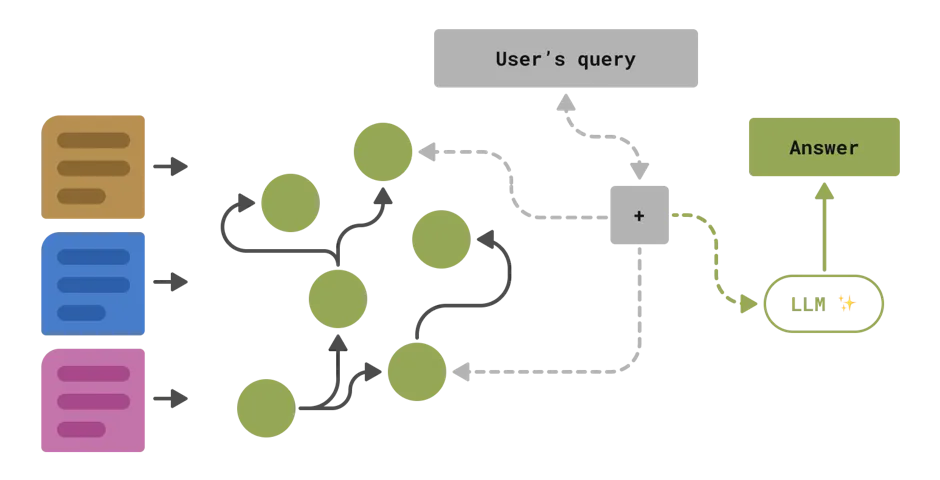
So which data structure should you choose? There are relational tables, maps, trees, graphs, and more. Each has its own pros and cons. Choosing which one to use depends on the implicit structure of your data as well as what you intend to query.
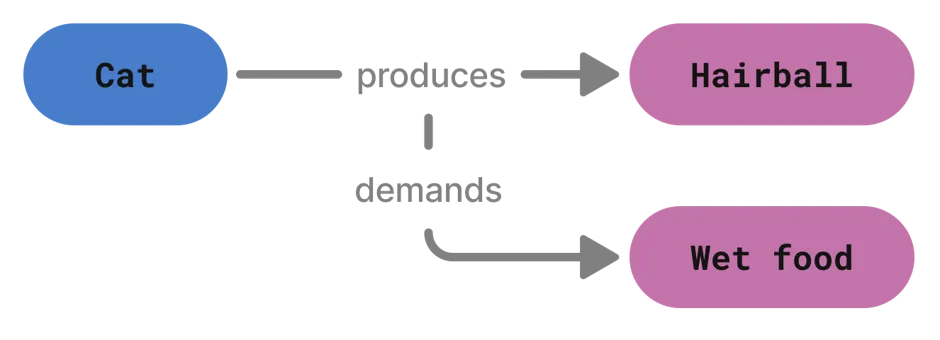
Graphs are the most common choice because they're well suited for representing relationships. Hence, if your application depends heavily on relationship information (e.g. (company X) -- sells --> (product Y), or, a much more real world example (cat) -- produces -> (hairball)), you should likely use a graph-based retrieval system.
Using a data-structure-centric approach does come with a tradeoff: you now have to create (and maintain) that data structure. Speaking of which, in the next section we'll take a look at how graphs get created.
What's a knowledge graph
Wait, first of all, what is a graph? It's a data structure that consists of nodes connected by edges. If nodes and edges can have arbitrary properties, that's called a property graph. The type and amount of information in each node, edge, or property depends entirely on your application. In a knowledge graph, nodes hold information about entities, and edges represent the semantic relationships between those entities.
For example, consider a graph like this: (cat) --- produces ---> (hairball). The ontology for this knowledge graph might specify two entities, cat and hairball plus a produces relationship that goes from cat to hairball (but not the other way around!)
There are two main angles you can take when converting your data into a graph:
-
lexical graph, also known as a document-level graph
-
domain graph, also known as an entity-level graph
Both terms and their underlying concepts have been around for a while, and they've recently re-emerged together in AI applications.
Lexical graph
This kind of graph is meant to capture the structure of the original text: how paragraphs are chained one after another, how they are grouped together into sections, which sections cross-reference each other, and so on. Intuitively, parts of the document that are tied by such relationships can be considered closely related, even though their vector-space representation may end up far apart.
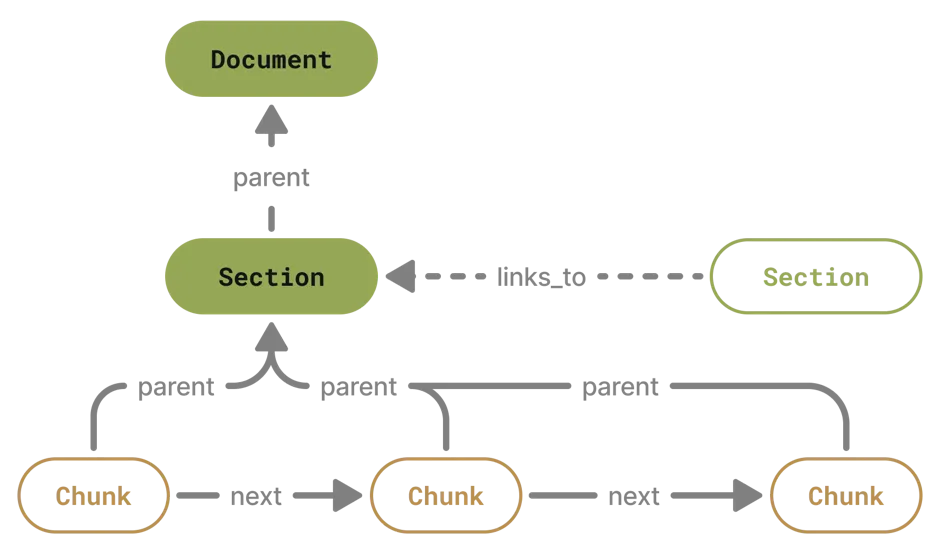
Defining the ontology and building this kind of graph is straightforward, although the process may be quite laborious. You have to resolve the references and keep track of all the links, which highlights the tradeoff of introducing this data structure to your RAG: increased ingestion and updating complexity.
Domain graph
Another approach is to create a what's called domain graph. In it, entities would be humans, objects, animals or any other subjects relevant to your application, and the relationships between them would represent, well, real-world semantic relationships.
Here we get to observe the controllability advantage graphs have over vector-based search: once you've extracted the relevant information into the graph, you get to use exact graph queries to find what you are looking for, as opposed to hoping that your vector query will magically align all the relevant chunks for you. We will talk more about querying graphs in one of the next sections.
Defining the ontology for a domain graph is far from an easy task, and it's only rivaled by having to extract relevant entities and their relationships from raw text.
First, let's consider how people did this in the pre-LLM times. The process would be typically broken down in four steps:
-
Coreference resolution: finding all the different ways the same entity gets mentioned in the text (and rewriting them in a unified way).
-
Named entity recognition (NER): finding all the entities that get mentioned within the text.
-
Entity linking: cross-referencing entities identified by NER with a predefined knowledge base.
-
Relationship extraction: recognizing relationships between different entities.

These days, of course, you can do all of this work implicitly by prompting your LLM with "please extract all entities or you go to jail.". If this results in excessive duplication and repetition in your case, you may consider a more sophisticated approach, such as asking the LLM to extract a predefined ontology curated by a human.
The tradeoff of using a domain graph is not difficult to see: while it may be incredibly powerful, that power comes at a cost of having to build and maintain a delicate preprocessing pipeline.
Complicated graph
If you've read this section so far and thought to yourself: "¿Por qué no los dos?", so did knowledge graph researchers. Thus we arrive at the hybrid graph, which simply links together various lexical and domain entities. With it comes incredible freedom in traversing your data, coupled with the increased overhead of managing two disparate ontologies.
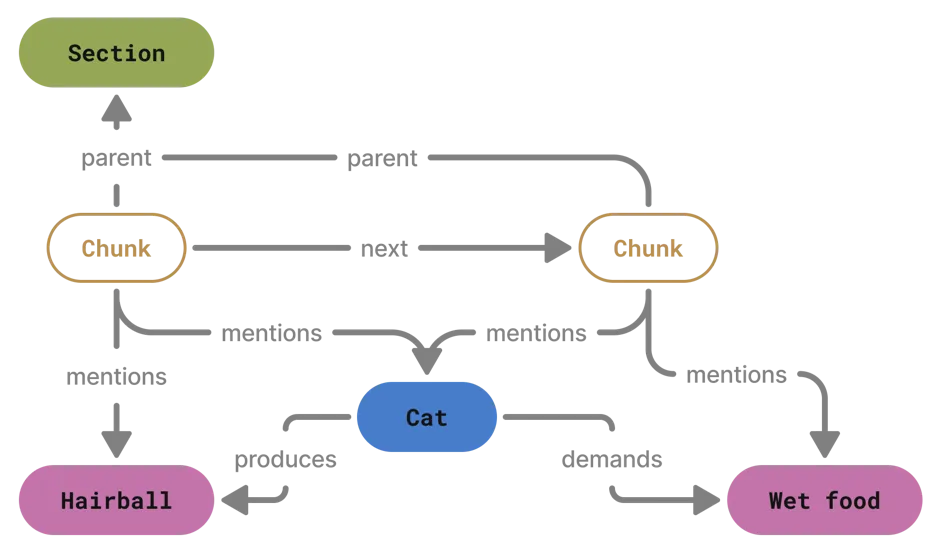
But that's far from the only way you could add more complexity to your graph, should your application demand it.
-
Remember node and edge properties? You could use those to encode temporal information. For example, Graphiti is a framework that's built on top of this idea.
-
You could go over every parent node in your graph, and attach to it an auto-generated summary of its children nodes.
-
Moreover, you could first run graph clustering algorithms to identify communities, and then generate summaries for those. That would enable you to capture implicit information that is spread across many loosely related chunks of raw text, and easily query for it. This is what Microsoft did in their famed GraphRAG [9] paper.
… and so on. At this point, your application's demands would dictate the direction of your research, and whether or not it's worth it to take another step up in complexity. If you are looking for a rigorous survey of different graph RAG patterns, you can check out Han et al. (2025).
Let's leave graph building at that, and move on to the next important topic.
How to use graphs in retrieval
Simple graph queries
The benefit of going through all the hoops described above is that we can now write normal graph queries to pull exactly the information we need, run them against the graph and append the result to the prompt.
Those queries could be fully premade or rendered on the fly using templates. Of course, we could also include a text-to-query step and generate those graph queries from natural language.
Vector search followed by graph algorithms
We briefly discussed the merits of vector search earlier in this post, and there's no reason not to leverage its flexibility in a graph RAG application.
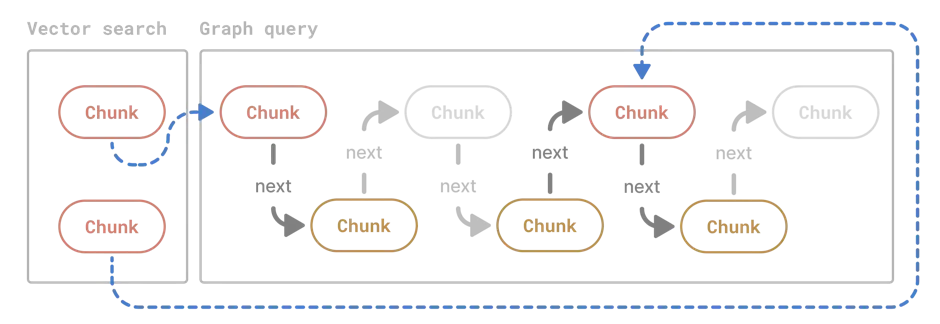
The common pattern is to run a vector search first to identify some initial set of nodes. Then, using each of those nodes as an entry point, run a simple graph query, e.g. capture the n-hop neighborhood to grab additional data that might not've been picked up by the vector search. This enables you to provide more cohesive context for the LLM, generally leading to improved RAG outputs.
Once your graph is sufficiently large, those graph queries will start bringing too many nodes to fit into the prompt. At this point you may decide to apply a reranking algorithm to identify the most relevant ones. Therein lies one more advantage of graphs: you can now use graph-based reranking algorithms, which is a popular move among graph RAG people [8]. You could go as far as PageRank, for example, which gained fame powering Google's search engine back in the day.
Vector search followed by subgraph derivation followed by graph algorithms
At some point, when things get complicated, it no longer makes sense to run certain algorithms on a raw graph.
Instead, at query time you could form a derivative graph that would emphasize and deemphasize certain nodes and relationships using a combination of filtering, virtual connections and edge weighting. For example, if you were keeping track of temporal information, now would be a good time to rearrange some of the nodes around that. Another typical strategy is to create direct virtual edges between leaf nodes that belong to the same parent. In reality, this step very much depends on your graph's overall ontology and shape.
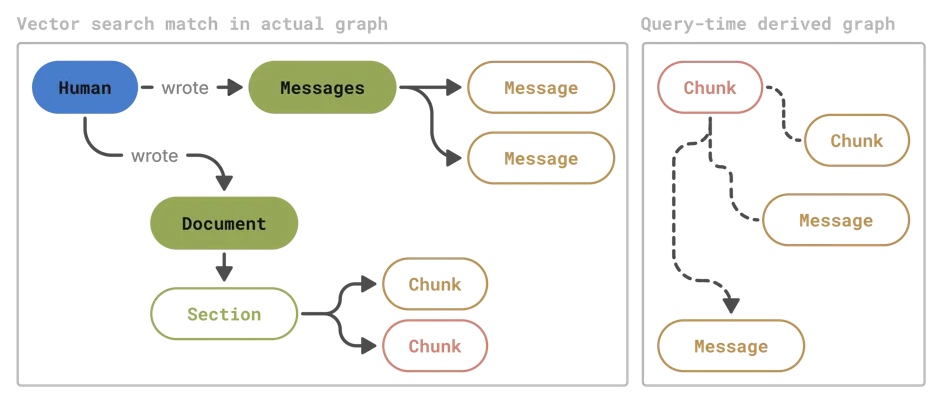
And as you can imagine, the complexity doesn't stop growing from here on.
As for us, we're going to leave it at that. Thank you for reading! And stay tuned for part 2, where we will focus on practical examples and even write some queries.
Acknowledgements
-
Artemy Belousov and Egor Kraev of motleycrew.ai fame for sharing their knowledge and insights on graph RAGs.
-
Tomaz Bratanic, "Entity Linking and Relationship Extraction With Relik in LlamaIndex" (Medium).
-
GraphRAG Pattern Catalog by Neo4j (graphrag.com)
[1] Barnett S. et al., "Seven Failure Points When Engineering a Retrieval Augmented Generation System" https://arxiv.org/pdf/2401.05856
[2] Balaguer A., Benara V., et al., "Rag vs. fine-tuning: pipelines, tradeoffs, and a case study on agriculture" https://arxiv.org/pdf/2401.08406
[3] Brown B. T. et al., "Language Models are Few-Shot Learners" https://arxiv.org/pdf/2005.14165
[4] Piktus A. et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" https://arxiv.org/pdf/2005.11401v4
[5] Modarressi A. et al., "NOLIMA: Long-Context Evaluation Beyond Literal Matching" https://arxiv.org/pdf/2407.11963
[6] Li M. et al., "NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?" https://arxiv.org/pdf/2407.11963
[7] Lee J. et al., "Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?" https://arxiv.org/pdf/2406.13121
[8] Dong J. et al., "Don't Forget to Connect! Improving RAG with Graph-based Reranking" https://arxiv.org/pdf/2405.18414
[9] Edge D. et al., "From Local to Global: A GraphRAG Approach to Query-Focused Summarization" https://arxiv.org/pdf/2404.16130


